 火星网校
火星网校
入门机器学习必备!五种回归损失函数
在机器学习中,损失函数是至关重要的一部分,用于衡量目标结果的好坏,用于训练模型,损失函数就是目标函数了。 L1、L2损失函数相信大多数人都早已不陌生。那你了解Huber损失、Quantile损失么?这些可都是机器学习大牛最常用的回归损失函数哦!今天就给大家分享五种回归损失函数,入门机器学习必备哦!
我们在进行机器学习的时候,使用的每一个算法都有一个目标函数,算法便是对这个目标函数进行优化,特别是在分类或者回归任务中。机器学习中的所有算法都依靠最小化或最大化函数,我们将其称为“目标函数”。被最小化的函数就被称为“损失函数”。损失函数也可以衡量预测模型在预测期望结果方面的性能。找到函数的最小值点的最常用方法是“梯度下降”。
损失函数,并非只有一种。根据不同的因素,包括是否存在异常值,所选机器学习算法,梯度下降的的时效,找到预测的置信度和导数的难易度,我们可以选择不同的损失函数。本文就带领大家学习不同的损失函数,以及它们如何在数据科学和机器学习中帮助我们。
损失函数可以大体分为两种类型:分类损失和回归损失。
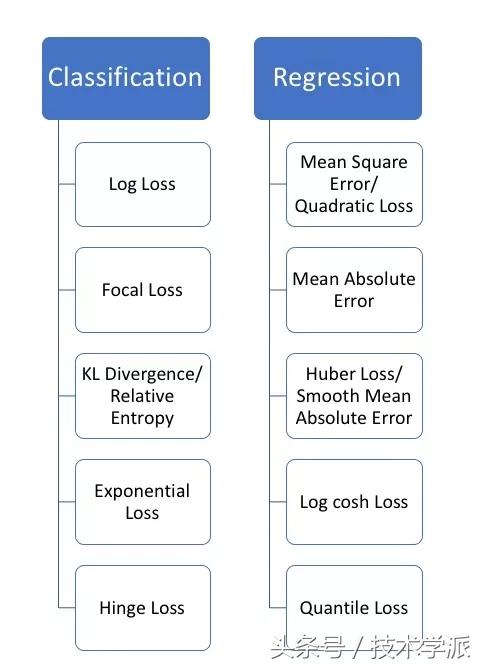
回归损失
均方误差(MSE),二次损失,L2损失
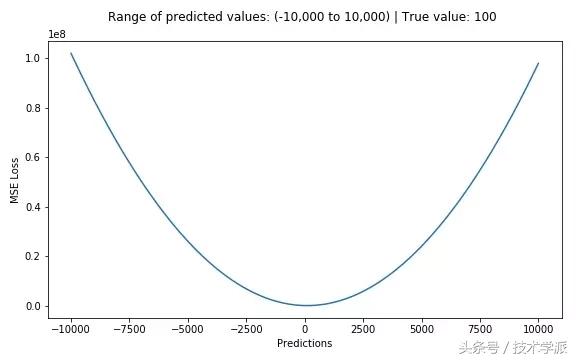
均方误差是最常用的回归损失函数,它是我们的目标变量和预测值的差值平方和。
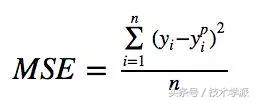
均方误差函数图
平均绝对误差,L1损失
平均绝对误差L1损失是一种用于回归模型的损失函数。是目标变量和预测变量之间绝对差值之和。因此它衡量的是一组预测值中的平均误差大小,而不考虑它们的方向。范围为0到∞。
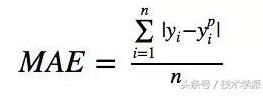
L2损失 vs L1损失
简而言之,使用平方误差更容易解决问题,但使用绝对误差对于异常值更鲁棒。我们来看一下为什么。
不管我们什么时候训练机器学习模型,我们的目标都是想找到一个点将损失函数最小化。当然,当预测值正好等于真值时,这两个函数都会达到最小值。
我们快速浏览一下这两种函数的Python代码。我们可以自己写函数,也可以用sklearn的内助度量函数:
# true: 真目标变量的数组
# pred: 预测值的数组
def mse(true, pred):
return np.sum((true - pred)**2)
def mae(true, pred):
return np.sum(np.abs(true - pred))
# 在 sklearn 中同样适用
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
我们来看看两种情况下MAE和均方根误差(RMSE,和MAE相同尺度下MSE的平方根)。在第一种情况下,预测值和真值非常接近,误差在众多观测值中变化很小。在第二种情况下,出现了一个异常观测值,误差就很高。
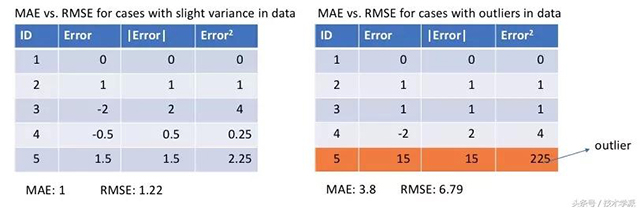
我们从中可以观察到什么?这怎样能帮我们选择使用哪种损失函数?
因为MSE是误差的平方值(y?—?y_predicted = e),那么误差(e)的值在e > 1时会增加很多。如果我们的数据中有异常值,e的值会非常高,e2会>> |e|。这会让存在MSE误差的模型比存在MAE误差的模型向异常值赋予更多的权重。在上面第2种情况中,存在RMSE误差的模型为了能将该单个异常值最小化会牺牲其它常见情况,这降低模型的整体性能。
如果训练数据被异常值破坏的话(也就是我们在训练环境中错误地接收到巨大的不切实际的正/负值,但在测试环境中却没有),MAE会很有用。
我们可以这样思考:如果我们必须为所有的观测值赋予一个预测值,以最小化MSE,那么该预测值应当为所有目标值的平均值。但是如果我们想将MAE最小化,那么预测值应当为所有观测值的中间值。我们知道中间值比起平均值,对异常值有更好的鲁棒性,这样就会让MAE比MSE对异常值更加鲁棒。
使用MAE损失(特别是对于神经网络来说)的一个大问题就是,其梯度始终一样,这意味着梯度即便是对于很小的损失值来说,也还会非常大。这对于机器学习可不是件好事。为了修正这一点,我们可以使用动态学习率,它会随着我们越来越接近最小值而逐渐变小。在这种情况下,MSE会表现的很好,即便学习率固定,也会收敛。MSE损失的梯度对于更大的损失值来说非常高,当损失值趋向于0时会逐渐降低,从而让它在模型训练收尾时更加准确(见下图)。
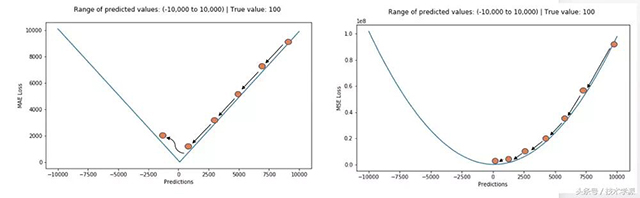
决定使用哪种损失函数
如果异常值表示的反常现象对于业务非常重要,且应当被检测到,那么我们就应当使用MSE。另一方面,如果我们认为异常值仅表示损坏数据而已,那么我们应当选择MAE作为损失函数。
如果想比较在有或没有异常值这两种情况下,使用L1和L2损失函数时回归模型的性能,建议读读这篇不错的研究。记住,L1和L2损失分别是MAE和MSE的别名。
L1损失对异常值更鲁棒,但它的导数是不连续的,从而让它无法有效的求解。L2损失对异常值很敏感,但会求出更稳定和更接近的解(通过将导数设为0)。
这两者存在的问题:可能会出现两种损失函数都无法给出理想预测值的情况。例如,如果我们的数据中90% 的观测值的目标真值为150, 剩余10%的目标值在0-30之间。那么存在MAE损失的模型可能会预测全部观测值的目标值为150,而忽略了那10%的异常情况,因为它会试图趋向于中间值。在同一种情况下,使用MSE损失的模型会给出大量值范围在0到30之间的预测值,因为它会偏向于异常值。在很多业务情况中,这两种结果都不够理想。
那么在这种情况下该怎么办?一个比较容易的修正方法是转换目标变量。另一种方法是试试不同的损失函数。这就引出了我们要讲的下一部分:Huber损失函数。
Huber损失函数,平滑平均绝对误差 相比平方误差损失,Huber损失对于数据中异常值的敏感性要差一些。在值为0时,它也是可微分的。它基本上是绝对值,在误差很小时会变为平方值。误差使其平方值的大小如何取决于一个超参数δ,该参数可以调整。当δ~ 0时,Huber损失会趋向于MAE;当δ~ ∞(很大的数字),Huber损失会趋向于MSE。
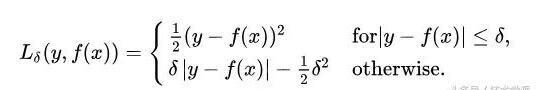
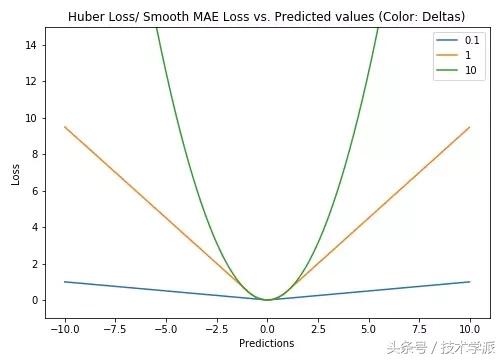
δ的选择非常关键,因为它决定了你如何看待异常值。残差大于δ,就用L1(它对很大的异常值敏感性较差)最小化,而残差小于δ,就用L2“适当地”最小化。
为何使用Huber损失函数?
使用MAE用于训练神经网络的一个大问题就是,它的梯度始终很大,这会导致使用梯度下降训练模型时,在结束时遗漏最小值。对于MSE,梯度会随着损失值接近其最小值逐渐减少,从而使其更准确。
在这些情况下,Huber损失函数真的会非常有帮助,因为它围绕的最小值会减小梯度。而且相比MSE,它对异常值更具鲁棒性。因此,它同时具备MSE和MAE这两种损失函数的优点。不过,Huber损失函数也存在一个问题,我们可能需要训练超参数δ,而且这个过程需要不断迭代。
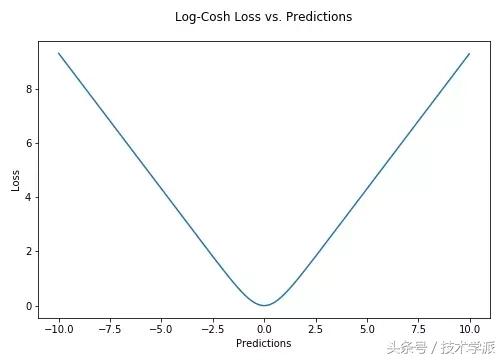
Log-Cosh损失函数
Log-Cosh是应用于回归任务中的另一种损失函数,它比L2损失更平滑。Log-cosh是预测误差的双曲余弦的对数。
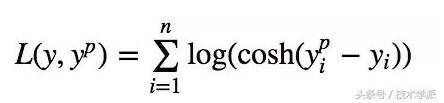
优点:
对于较小的X值,log(cosh(x))约等于(x ** 2) / 2;对于较大的X值,则约等于abs(x) - log(2)。这意味着Log-cosh很大程度上工作原理和平均方误差很像,但偶尔出现错的离谱的预测时对它影响又不是很大。它具备了Huber损失函数的所有优点,但不像Huber损失,它在所有地方都二次可微。
我们为何需要二阶导数?很多机器学习模型,比如XGBoost,使用牛顿法来寻找最好结果,因此需要二阶导数(海塞函数)。对于像XGBoost这样的机器学习框架,二次可微函数更为有利。

Huber损失函数和Log-cosh损失函数的Python代码:
# huber 损失
def huber(true, pred, delta):
loss = np.where(np.abs(true-pred) < delta , 0.5*((true-pred)**2), delta*np.abs(true - pred) - 0.5*(delta**2))
return np.sum(loss)
?
# log cosh 损失
def logcosh(true, pred):
loss = np.log(np.cosh(pred - true))
return np.sum(loss)
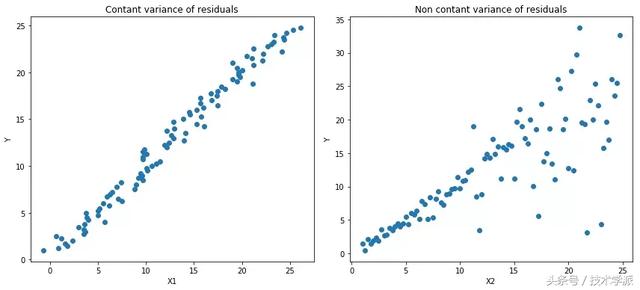
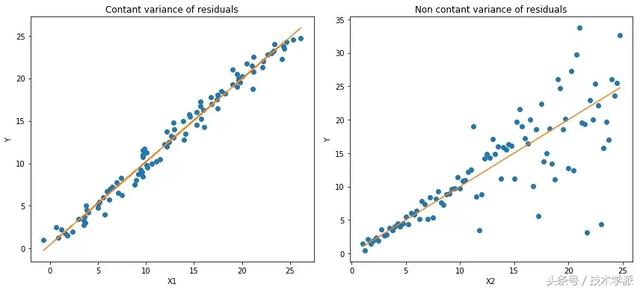
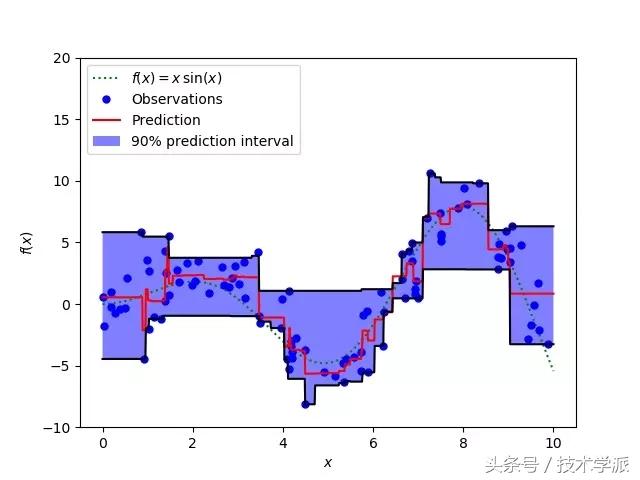
Quantile损失函数 在大多数现实预测问题中,我们常常很想知道我们的预测值的不确定性。对于很多业务问题而言,相对于知道某个预测点,了解预测值范围能够大幅优化决策过程。最小二乘回归的预测区间基于我们假设残差值(y?—?y_hat)在所有独立变量值上的变化保持一致。
如果我们是想预测某个区间而非某个点,Quantile损失函数会非常有用。违背此假设的回归模型是不可信的。当然我们也不能认为这种情况下用非线性函数或基于树的模型能更好的建模,把拟合线性模型作为基准的理念扔在一边就完了。这时,我们就可以用到Quantile损失和Quantile回归,因为基于Quantile损失的回归能够提供更明智的预测区间,即便是有非常量方差和非正常分布的误差来说,效果同样不错。
我们来看一些案例,更好的理解为何基于Quantile损失的回归能对异方差问题效果良好。
Quantile回归 VS 普通最小乘二回归
理解 Quantile 损失函数
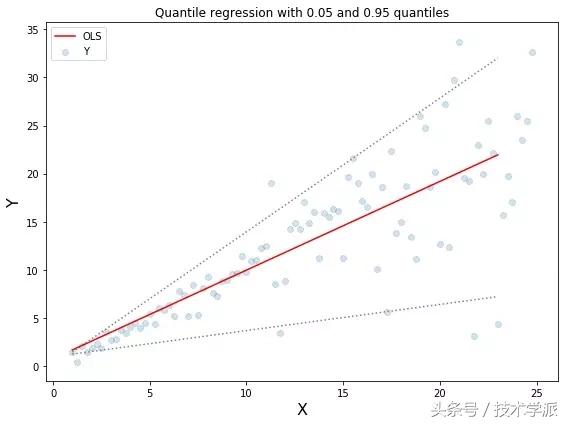
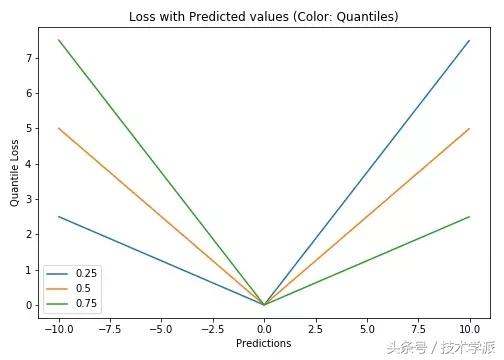
基于 Quantile 的回归模型目的是根据预测变量的特定值,预测反应变量的条件分位数。 Quantile 损失实际上就是 MAE 的延伸(当分位数为第50个百分位数时,它就是MAE)。
其理念就是根据我们是否想增加正误差或负误差的分量选择合适的分位数值。损失函数会根据所选分位数(γ)的值,为估计过高或估计不足做出不同的处罚。例如,γ=0.25的Quantile损失函数会向估计过高做出更多的惩罚,将预测值保持在略微低于平均值的状态。
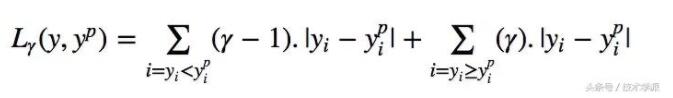
比较研究
为了展示以上所有损失函数的属性,文章作者模拟了一个取样于sinc(x)函数的数据集,以及两个人工模拟噪声数据集:高斯噪声分量ε ~ N(0, σ2),以及脉冲噪声分量ξ ~ Bern(p)。作者添加了脉冲噪声项来说明鲁棒影响。下图是用不同损失函数拟合GBM回归模型的结果。
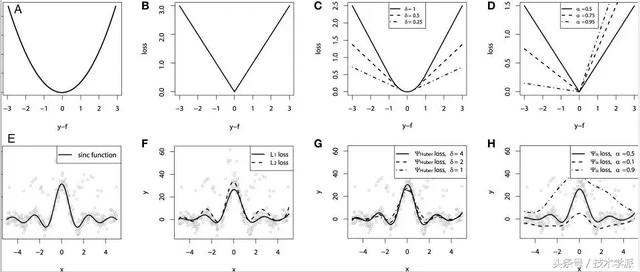
图中依次为(A)MSE损失函数 (B)MAE损失函数(C)Huber损失函数(D)Quantile损失函数(E)原始sinc(x) 函数(F)拟合了MSE和MAE损失的平滑GBM(G)拟合了huber损失为 δ = {4, 2, 1}的平滑GBM(H)拟合了Quantile损失为α = {0.5, 0.1, 0.9}的平滑GBM
从以上模拟中我们可以观察到:
有MAE损失的模型预测值受脉冲噪声的影响较小,而有MSE损失的模型预测值由于噪声数据导致的偏差,则出现轻微偏差。
有Huber损失的模型预测值对于所选超参数的值敏感度较小。
Quantile损失在对应置信度水平上做出了很好的预测。
最后我们把以上所有损失函数绘制在一张图中:
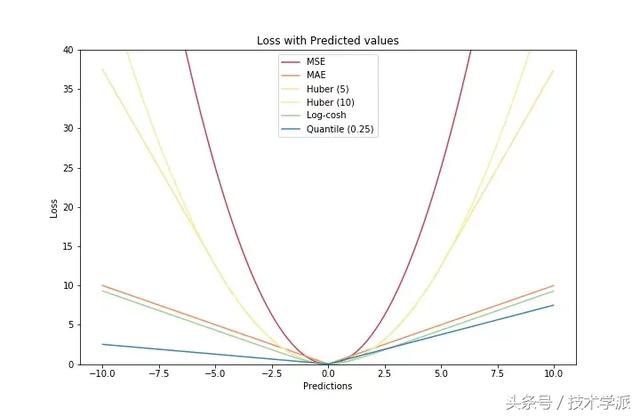
来源:技术学派头条号




上一篇 python快速编程入门教程
-

2101期学员李思庭作品
-

2104期学员林雪茹作品
-

2107期学员赵凌作品
-

2107期学员赵燃作品
-

2106期学员徐正浩作品
-

2106期学员弓莉作品
-

2105期学员白羽新作品
-

2107期学员王佳蕊作品
热门课程
专业讲师指导 快速摆脱技能困惑



相关文章
多种教程 总有一个适合自己专业问题咨询
你担心的问题,火星帮你解答-
可灵年化5亿美元谷歌带队出海安徽举办省级漫剧大赛AI设计日报0623
可灵正推进从快手分拆独立运营,内部方向为2027年初递交港股上市申报 来源:上海证券报(2026-06-17) AI短剧"产......
-
火星时代
-
腾讯又放大招这款AI工具让游戏美术效率提升300是真革命还是噱头
但对于追求极致细节的资深原画师来说,自动化程度高也意味着部分控制权让渡,需要适应 实测体验:响应速度确实惊艳,比传统生图的等待......
-
2026年,AI短剧早已不是"写一段提示词等生成"的粗放阶段真正拉开差距的,是谁先把从立项到出片的整套工业化流程跑通 过去做A......
-
什么是负面提示词? 在AI绘画中,我们通常用正向提示词告诉模型想要什么——比如"一个穿红色连衣裙的女孩站在海边"这时候你需要一......
-
做AI漫剧最头疼的是什么?不是剧情写不好,不是场景出不来——是角色脸上的表情 想写角色开心,只会一句"他开心地笑了";想写难过......
