 火星网校
火星网校
HZB是什么?如何在UE4移动端中实现HZB?
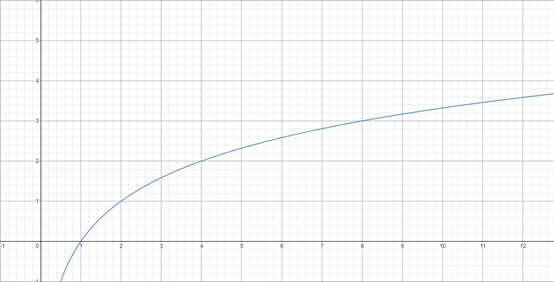
Hierarchical Z-Buffering分层Z缓冲(HZB)对遮挡剔除研究具有重要影响,是GPU Driven Rendering Pipeline的重要剔除手段。目前部分主流商业引擎可能因为某些原因导致该技术无法完全在GPU端工作,但依然是值得探讨的。本文先介绍HZB的基本原理以及UE4在PC端的实现方式,然后介绍如何移植到移动端并分析其性能和带来的价值,以及未来还可以做的工作。
一、HZB的原理
一般来说,大多数基于HZB的遮挡剔除是这样的工作的:
1. 使用一些遮挡器生成一个完整的分层Z-金字塔。
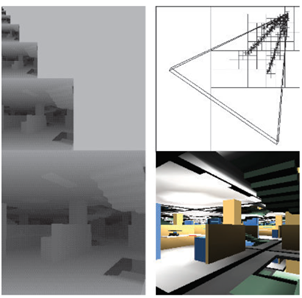
z-pyramid的最低级别是一个标准的z-buffer。在所有其他层,每个z值都是上一层对应的2×2像素中最远的z。
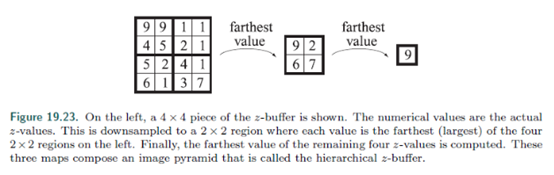
2. 要测试的对象是否被遮挡,可以将其包围体投射到屏幕空间,并在z-pyramid中估计mip级别。将对象的包围体投影到屏幕空间。最长的边l(像素)用来计算mip等级λ。
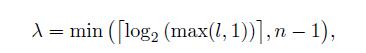
边长越长,选取的mip等级越高。
3. 根据选定的mip测试遮挡。如果结果不明确,可以继续使用更细的mip级别进行测试。
这个选择的原因是它使成本可预测——最多需要读取和测试四个深度值。此外,这种测试可以被看作是“概率性的”,因为大对象比小对象更容易被看到,所以在这些情况下没有理由读取更多的深度值,即节省了带宽,也增加了Cache命中。
二、UE4的实现
UE4只在PC端进行了实现,过程大致一样,不同的是在构建层级Z缓冲上分为ComputeShader和PixelShader两种方式,然后最终剔除工作主要在CPU端进行,意味着需要回读GPU的测试结果。以下是UE4的工作流程:
1. 使用SceneDepth作为数据源构建层级Z缓冲。Mip0为第一级,大小为1024*512,总共构建10级。分为两种方式,PixelShader方式比较简单,一次构建一级,总共执行十次。ComputeShader则稍微复杂一点,利用GroupMemoryBarrierWithGroupSync,每次同时构建4级,总共只要执行3次,便完成构建。
2. 场景中的物体经过视锥剔除以后,剩下的会被收集起来,存放在一个数组中,并且每个物体会保存自己在数组中的索引值。然后,创建2张RGBA32格式的贴图,一张存放物体包围盒的质心坐标,一张存放物体包围盒的大小。每次从数组中取64个物体作为一组,保存到贴图的64个像素区域中。
3. 采样第二步中的贴图,获取物体的质心坐标和包围盒大小,可以计算出物体包围盒的八个顶点的世界位置,对这八个顶点进行投影,选取其中最近的Z值。根据投影后的矩形区域,选取最长边长计算mipmap等级,然后在矩形区域内采样该mipmap的16个像素,选取其中最远的Z值。如果包围盒最近的Z值比它还小,则物体不可见。将结果保存到一张格式为RGBA8的RenderTarget中,作为下一帧读取。
4. 当前帧读取上一帧的贴图数据到一个数组中。每个物体将上一帧保存的数组索引到该数据进行查询,查询结果决定了该物体在当前帧的可见性。
以上步骤看出,UE4的HZB实现流程没有完全放在GPU端执行,在下一帧的时候需要回读上一帧的结果,然后进行查询以决定物体当前帧的可见性。另外,在第三步中,计算最远Z值时,采样了矩形区域内16个像素,而不是4个像素。
三、移动端的实现
移动端的HZB方案大部分可以与PC端共用一套逻辑实现,然后针对移动端性能点进行优化。移动端需要解决的第一个首要问题就是SceneDepth的获取,因为它是构建层级Z缓冲的重要数据来源。
在移动端上,一般来说,如果存在后处理材质需要访问场景深度信息,UE4会将场景线性深度值保存在SceneColor的Alpha通道。而对于透明材质,如果使用了DepthFade材质节点,则会通过移动设备扩展API来直接提取FrameBuffer中的深度信息。
那我们如果想在移动端上直接访问深度纹理的话,需要怎么做了?可以通过设置r.Mobile.ForceDepthResolve为1来始终保留移动端的深度信息。强制深度解析,为设备保留深度纹理。

移动端获取深度纹理

获取了深度纹理,就可以开始构建层级Z缓冲。考虑到移动设备的兼容性,这里只使用了PixelShader方式,依然构建了10级mipmap。为了保证深度值的精度,这里将每个深度值编码到rgba8888格式的贴图中。
移动端构建层级Z缓冲
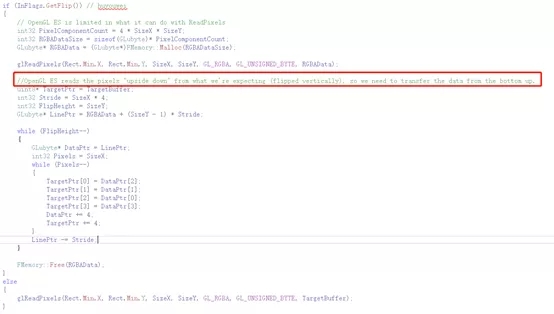
构建完层级Z缓冲以后,接下来就是进行遮挡测试。算法沿用了PC端的方式,将结果保存在贴图中,下一帧回读。移动端上回读GPU贴图数据,需要注意的是,UE4会默认处理上下翻转。因为这里只是存放遮挡结果的数据贴图,所以不需要做上下翻转。
最后一步遮挡查询,过程和PC端一样,每个物体用上一帧的数组索引去查询自己当前帧的可见性。
优化读取性能
移动端回读GPU数据相当耗费性能,我们可以来看下glReadPixels分别在oppo手机型号为r15和r17上的测试结果:
r15耗时6~8ms

r17 耗时 16~20ms
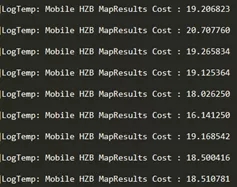
直接调用glReadPixels相当慢,不过,好在目前大多数移动设备的opengles已经达到3.0以上,所以,可以考虑使用PBO的方式进行优化,使用 glMapBufferRang进行读取。过程大致如下:
1.初始化2个buffer。
2.buffer1用于异步glReadPixels读取,buffer2用于glMapBufferRange读取。
3.下一帧交换buffer,buffer1用于glMapBufferRange,buffer2用于glReadPixels。
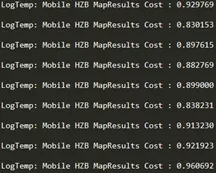
再来看下,优化后的测试结果:
优化后,r15耗时0.9ms
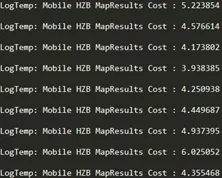
优化后,r17耗时4~6ms
硬件遮挡查询 和 HZB在oppo r15上的性能对比
经过初步优化,我们来看下,硬件遮挡查询和HZB各自在手机上的性能对比。测试分为静态物体和动态物体。新建一个场景,场景内随机生成10000个物体。在分别只开启硬件查询和只开启HZB的情况下,对帧率和被遮挡物数量的影响。UE4针对硬件查询做了Batch优化,这样可以大大降低硬件查询带来的DC开销,不过Batch只对静态物体有效。所以,需要分开测试。
动态物体:
如图,只开启了硬件查询,因为动态物体无法Batch,Occlusion queries相当高,达到987,而draw call数量达到了1450。被遮挡物体为579,可见物体为411。帧率只有18。由此可见,对于大量动态物体,硬件查询本身带来了巨大的DC开销。

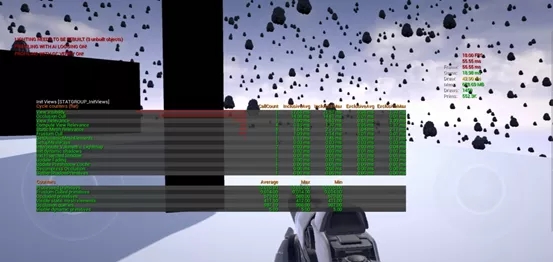
如图,只开启了HZB,硬件查询的DC开销已经没有了,被遮挡物体为570,可见物体为420。Draw call为467,帧率为30。


结论:对于大量动态物体查询的场景,从被遮挡物体数量和可见物体数量两个数据指标来看,硬件查询和HZB不相上下。性能上,HZB优势明显。
静态物体:
如图,只开启硬件查询,因为静态物体的原因,硬件查询发挥了Batch的优势,Occlusion queries只有58,draw call只有511,帧率达到35。


如图,只开启了HZB,硬件查询Batch带来的DC也没有了,所以draw call略有下降。帧率为33。


结论:对于大量静态物体查询的场景,HZB仍适用,性能与硬件查询Batch相当。
硬件遮挡查询 和 HZB在oppo r17上的性能对比
同样分别测试动态物体和静态物体,r17和r15表现了完全的不一样的结果,之前在优化读取时也发现,r17依然有4~6ms的开销,这是为什么了?这跟r15和r17在硬件上不同有关。
R15硬件参数
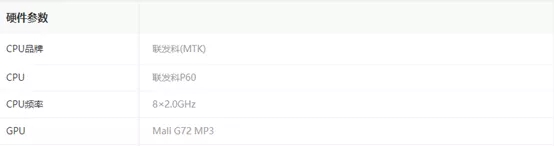
R17硬件参数
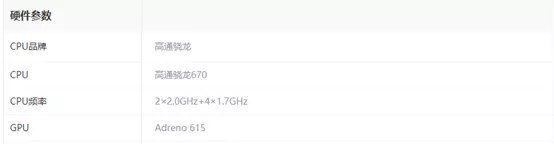
另外,值得一提的是,UE4针对高通设备,做了硬件查询的上限限制。最大510次查询,而其他设备默认是最大4000次查询。
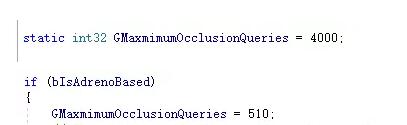
这导致了R17在大量动态物体场景下,即便没有做Batch,也只有不超过250的Occlusion queries数量。这并不是什么优化,而是UE4直接放弃了超过该数量的硬件查询,再加上依然存在的回读耗时,这样使得HZB的优势就不那么明显了。
如图,R17上,开启硬件查询,关闭HZB。

如图,R17上,关闭硬件查询,开启HZB。

结论:基于以上原因,在大量动态物体和静态物体场景下,HZB在R17上都表现不佳。
其他性能开销
移动端除了回读耗时以外,在HZB构建以及遮挡测试阶段,性能消耗也不能忽视,特别是采样16次贴图的操作。如下分别是在R15和R17上的测试结果:
R15在构建和测试阶段分别耗时2.6ms和1.6ms。回读耗时0.9ms

R17在构建和测试阶段分别耗时0.48ms和0.41ms。回读耗时5.2ms

通过对比发现,R15回读快,而构建慢。R17回读慢,而构建快。不同的硬件架构带来的性能差异很大,关于移动硬件分析已经不属于本文探讨范畴了,在这里就不展开讲了。
四、总结
关于UE硬件查询的Batch结论:
1.动态物体不会做Batch,全部一个一个去查询,带来巨大的DC开销。
2.静态物体在被遮挡的情况下会做batch查询,DC显著减少。
3.高通手机最大查询次数为510,其他为4000,而实际推荐最佳查询次数是250,2000(分别除了2)。
移动端HZB结论:
大量动态物体查询,HZB适用于非高通移动设备上。
大量静态物体查询,HZB仍适用于非高通移动设备上,性能与硬件查询Batch相当。
针对移动端未来可以做的优化方案:
1.将物体数据由质心坐标+包围盒范围改为质心坐标+包围球半径,可节省一张RGBA32贴图。
2.将16次采样改为采样包围球表面最近点和包围盒四个顶点,可减少11次采样。甚至更保守点,直接将包围球面最近点作为采样点进行比较。
3.高通设备可以考虑使用vulkan图形API进行数据回读。
4.高通设备在构建HZB的时候可以考虑使用ComputeShader。
作者:Youwei
来源:腾讯GWB游戏无界




上一篇 如何在UE4中制作非写实水面
下一篇 UE新功能介绍分享
-

2101期学员李思庭作品
-

2104期学员林雪茹作品
-

2107期学员赵凌作品
-

2107期学员赵燃作品
-

2106期学员徐正浩作品
-

2106期学员弓莉作品
-

2105期学员白羽新作品
-

2107期学员王佳蕊作品
热门课程
专业讲师指导 快速摆脱技能困惑



相关文章
多种教程 总有一个适合自己专业问题咨询
你担心的问题,火星帮你解答-
可灵年化5亿美元谷歌带队出海安徽举办省级漫剧大赛AI设计日报0623
可灵正推进从快手分拆独立运营,内部方向为2027年初递交港股上市申报 来源:上海证券报(2026-06-17) AI短剧"产......
-
火星时代
-
腾讯又放大招这款AI工具让游戏美术效率提升300是真革命还是噱头
但对于追求极致细节的资深原画师来说,自动化程度高也意味着部分控制权让渡,需要适应 实测体验:响应速度确实惊艳,比传统生图的等待......
-
2026年,AI短剧早已不是"写一段提示词等生成"的粗放阶段真正拉开差距的,是谁先把从立项到出片的整套工业化流程跑通 过去做A......
-
什么是负面提示词? 在AI绘画中,我们通常用正向提示词告诉模型想要什么——比如"一个穿红色连衣裙的女孩站在海边"这时候你需要一......
-
做AI漫剧最头疼的是什么?不是剧情写不好,不是场景出不来——是角色脸上的表情 想写角色开心,只会一句"他开心地笑了";想写难过......
