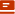 火星网校
火星网校
Maya Mental Ray加速渲染的一些小技巧:渲染设置篇

今天小编给大家带来的是关于Maya Mental Ray加速渲染的一些小技巧,分享给大家,希望可以帮助到大家的学习!
文章转载于雪人明明的QQ空间,地址:http://user.qzone.qq.com/641454768/2
mr(mental ray)3.12是maya2015集成的最新的OEM版本,这个版本和之前的版本在渲染机制与UI上差别很大。
PS:其实在Maya2014里就已经更新成这个界面,只不过在2015里面更加的成熟与稳定了。
在渲染的上舍弃了之前的采样渲染方式,全新采用了最新的一种叫做统一采样(Unified Sampling)的技术,据官方说明这种技术在渲染上会加速很多,据说VR已经采用了这项技术于自己的渲染中,具体的关于该技术的运行方式请参考官方的文档,网上也有不少关于该技术的视频教程,至于UI的变化请参见下图红框内:

既然渲染采样已经采用了新的技术,那么之前的品质控制选项也得到了相应的优化,现在的品控基本优化为3项,可以在渲染设置上方的Presets中打开,如下图:
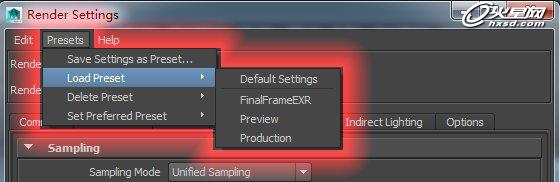
之前总结了关于反射的shader的优化,但是没有关于带有折射透明属性的优化调节,我想结合一下渲染设置面板,来说一下关于折射透明物体的优化,在mr的渲染中,凡是带有折射透明的物体最好使用mr自身的mia_material_x_passes这样有几点好处:
1.mr自身的mia_material_x_passes在调节在调节透明折射属性的时候自身带有很多预设,可以很轻松的创建,而不用像Maya自身shader那样需要额外连接多余的节点。
2. mia_material_x_passes自身有很多优化前选项,效率不输甚至更胜Maya自身的shader。
3.mia_material_x_passes在mr新的统一采样的渲染机制下更为快速和易于控制。
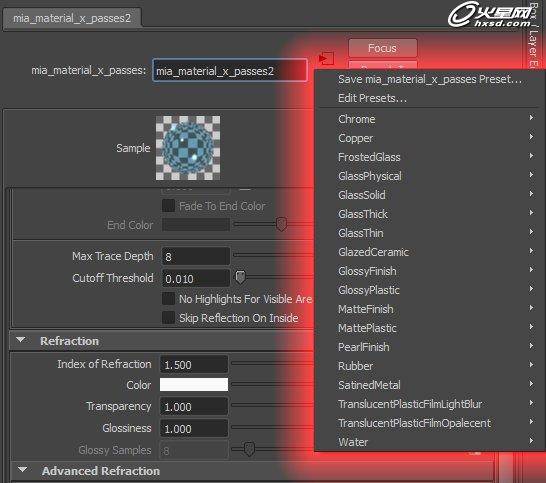
mia_material_x_passes在max的mr当中被统一叫做建筑材质,在Maya和Max的界面中如下:红色框内为Maya,绿色框内为Max。
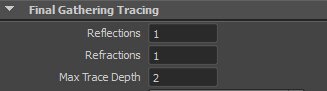
首先,渲染这种折射透明属性主要在渲染设置面板需要用到光线追踪的选项,主要在渲染模版需要调节的就在于这个选项下,如图:
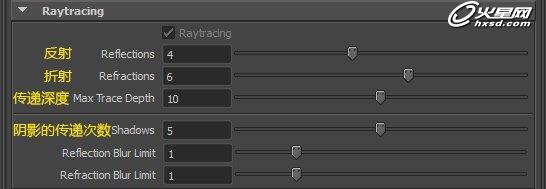
那么以上是成品品质的各个参数的数值,我们先看一下现在的参数渲染的时间和效果:
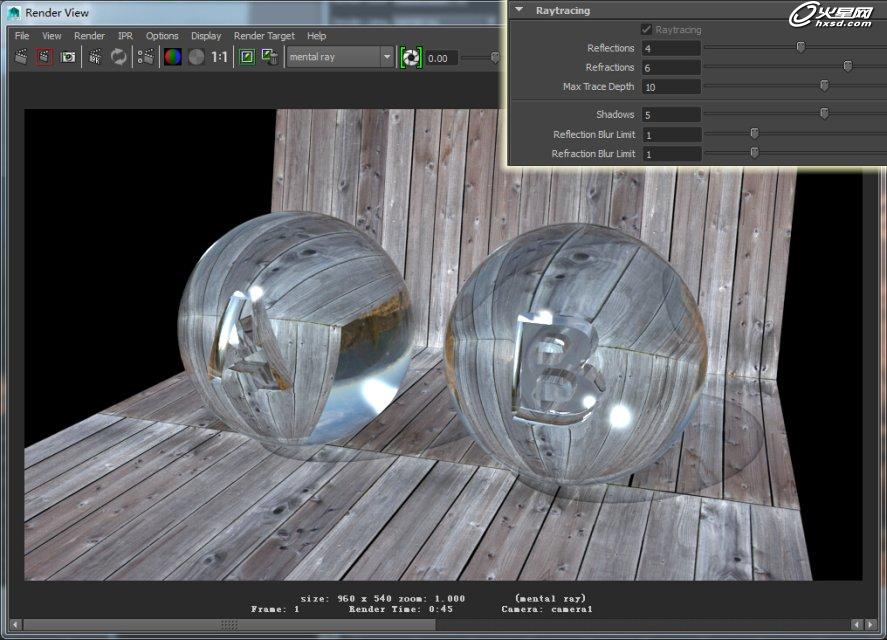
此场景在默认情况下的渲染时间为45秒(此场景已经开启fg),那我们来看一下,调节参数后的渲染时间。
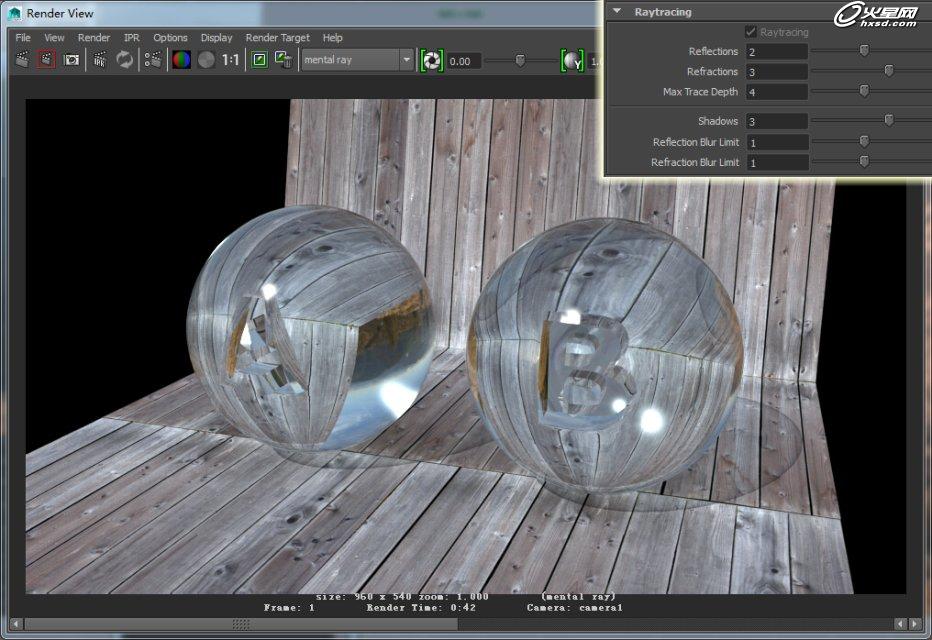
将参数调整完的渲染时间缩短了3秒,其实不要小看这3秒,只是调整了这一方面的参数缩短的3秒钟在渲染序列的时候会有很大的效率提升,虽然画面有稍许区别,但是在渲染时间和画面之中找到一个平衡点才是渲染的根本,而不是局限于只追求物理上的精确。那么是不是在降低点参数就会更快呢,这是必然的,但是在降低参数换来的不但是物理上的不准确,而且在视觉上也不讨好,下面就是再次降低参数换来的结果。
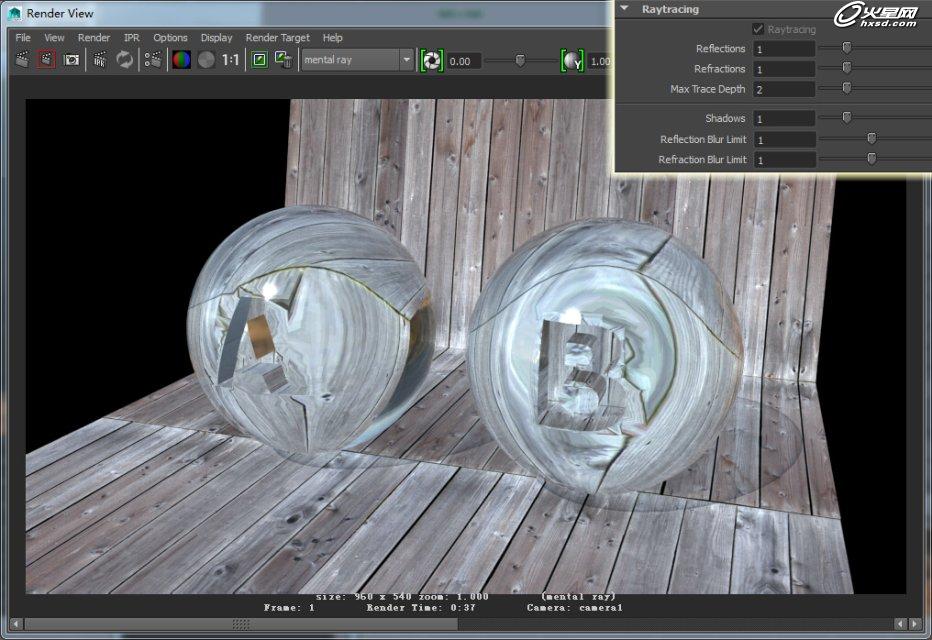
可以看到虽然渲染时间快了,但是换来的画面质量和效率并木有取得一个很好的平衡点,这样的渲染显然不是一个渲染人所需要的。
PS:其实之前的渲染时间并不十分准确,之前的测试我电脑开了很多程序,用了很长时间。而当我重新启动电脑,并且只开启Maya的时候,渲染时间比之前至少要缩短5秒,但是上述测试时间并不影响相对的速度,也就是说,参数调整之后确实是要比没调整之前要快,只不过现在相对应的都减少了一些时间而已。
接下来说完渲染设置对透明折射shader的影响之后,就要结合shader自身的优化说一下mr的mia_material_x_passes,同样在透明折射方面也有自己的优化。
下面我们看一下mia_material_x_passes在这方面的优化,在反射一栏的高级选项里有一项叫做跳过内部的反射,默认是勾选的。也就是说当你使用透明折射属性后,默认是不计算内部的反射,只计算表面,虽然结果不是很物理精确,但是在不影响大局的情况下速度会显著提升,下面我们看看打开和关闭这个选项的渲染结果,如下图:
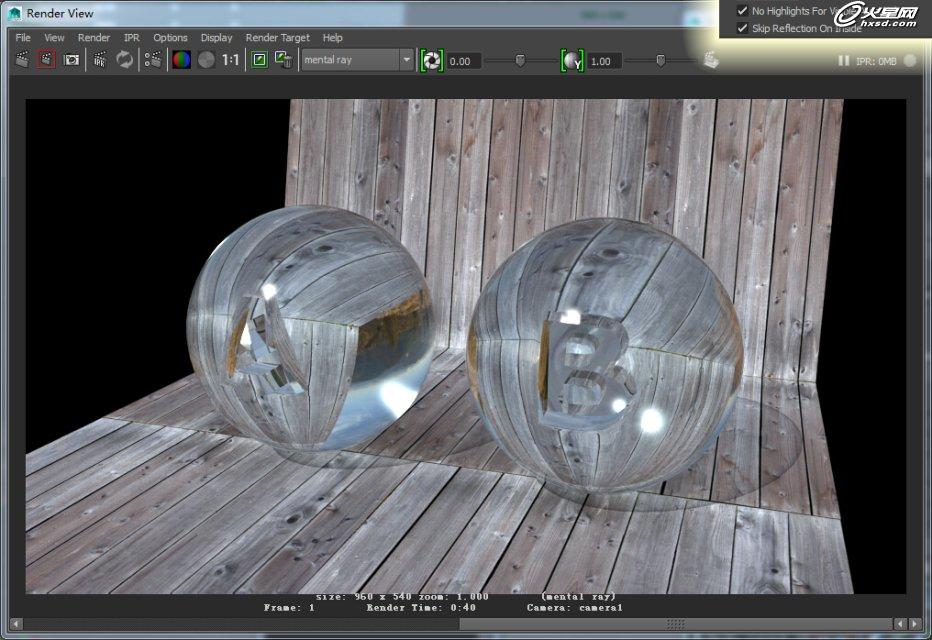

看上去似乎只有时间上的区别,并木有什么大的变化,这就是为什么mr会默认打开跳过内部反射的原因,但是仔细看,你会发现如果计算内部反射会带来更丰富的反射效果,这只是简单的球体。如果是项目中很复杂的形体那么结果会更明显,也会更漂亮。但是随之而来的渲染时间会相应的增加,需要一些权衡和技术手段的调控,如下图红圈内标注:

在渲染面板的fg选项里,还有一点会影响到折射透明属性的选项需要说明,就是fg射线也有穿过物体内部的选项,但是一般情况下保持默认足矣,这个提升画质的效果并不是特别明显,只是亮度上的增加和饱和度的变化而已,如下图:
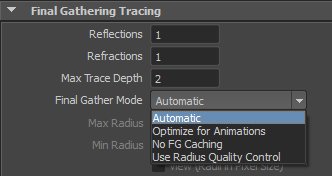
接下来简单说一下mr的主要利器fg(Final Gathering ) ,其实现在大多数渲染器基本都具备这个功能,只不过每个渲染器的这个功能的名字不一样,其实大同小异。关于fg,我不谈太多了,其实有些东西参数什么的我也没有完全掌握明白,大多数是靠平时工作的一些经验来设置数值,真正用的好的,完全理解的,国内大神级别人物很多,我现在是肯定没有达到的,只能浅谈一下这个功能。其他的参数不表,单独说说fg在相同参数下的噪点抑制的一个小小的技巧,fg的采样模式有4种,默认的采样是Automatic(自动方式),如下图:
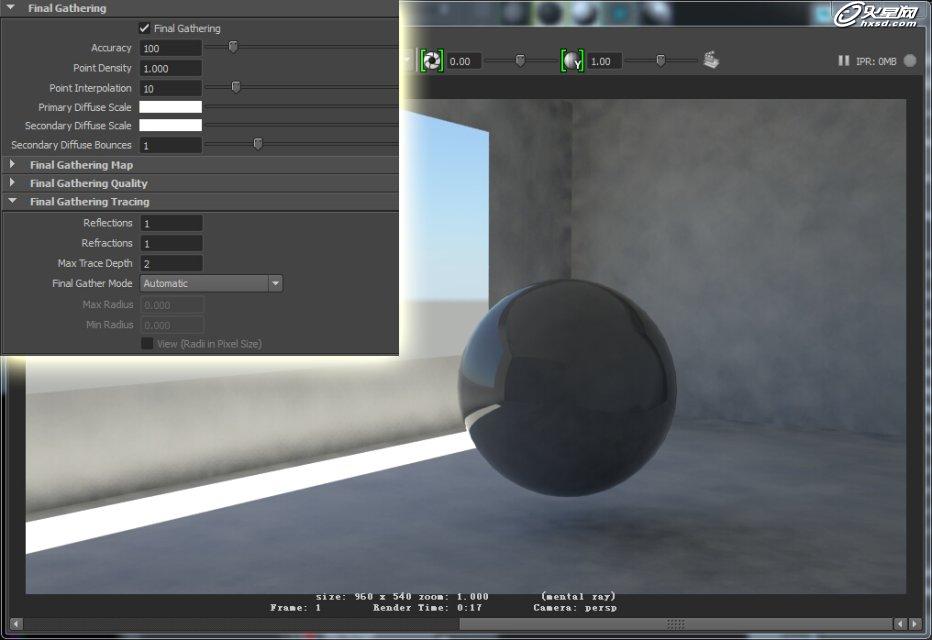
这种方式在默认的参数下早点控制是不好的,也就是说fg的采样如果很低,就算保持默认,那么以这种方式计算,会有很多噪点,尤其如果场景是半封闭的情况下,此情况更为严重,如下图:
但是如果保持fg的采样参数相同的情况下,调整一下采样模式,那就会大大改善现有的情况,如下图:

将采样模式改为动画优化模式,噪点大大减少,而且这种模式是为了减少动画闪烁而研发的,在渲染动画的时候选择这一项可以大大减少fg闪烁,而且在渲染序列帧的情况下会有加速效果。当然在避免fg闪烁的方面还要有其他措施相辅助,网上教程很多,这里就不一一阐述了。那么在这一个模式下不用太多的增加fg采样就可以达到比较光滑的效果,只要稍微增加一些,就可以收到不错的平滑效果了。以下是配合mr的窗口入射光渲染得到的结果:

另外需要说明的是场景中可以单独设置每个物体不同的fg采样,这样打来的好处就是场景中所有物体不用同样采样数,大场景,比如上图的室内就可以单独为它设置高采样,小物体,比如上面的球体可以单独设置低采样,这样极快的加速了渲染,同时也能保证精度。
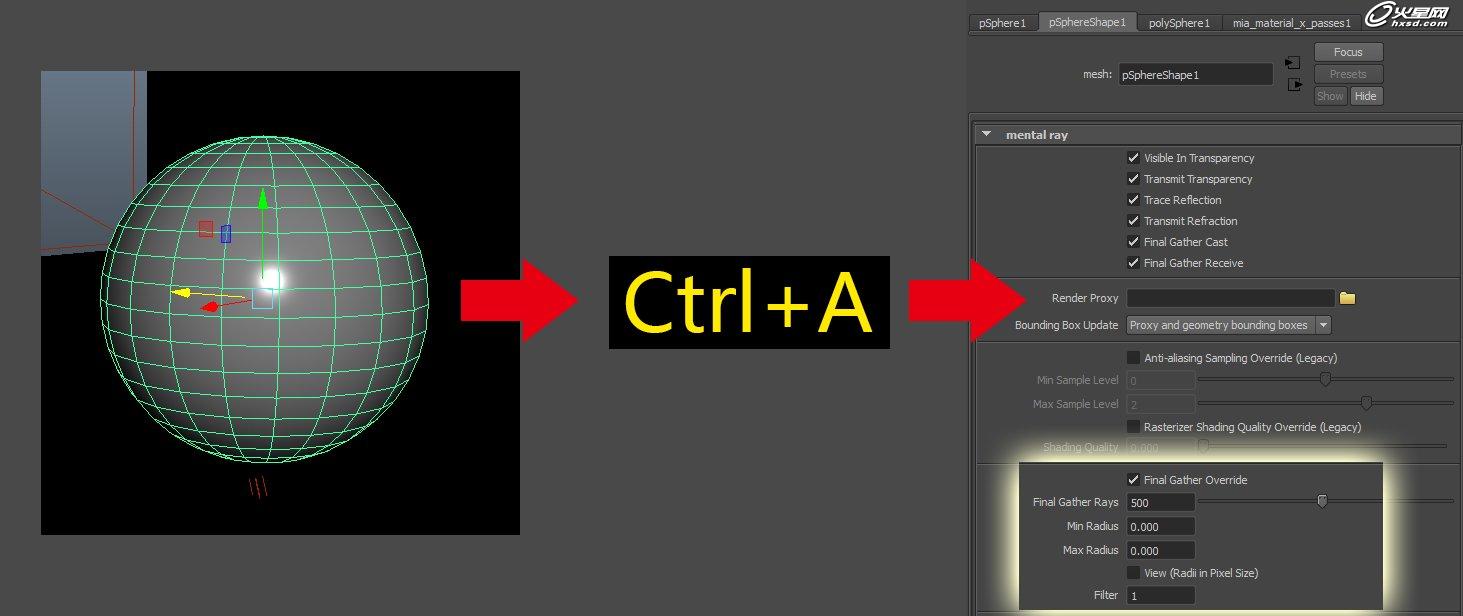
如果想为物体单独设置采样,具体方法是在场景中选择物体,按键盘Ctrl+A调出物体属性,并且在Mental Ray下面找到Final Gather Override设置合理参数,如下图:
更新内容:
1.fg方面的优化,其实这方面的优化分2种。一种是对于静幀图像,而另一种是对于动画渲染序列而言的。2种的优化既有联系也有不同,其实我要讲的可能还没有深入到最底层,是浅尝辄止,简单说一下,也是平时工作的一些经验。可能有一些误解,但是按照本人现在的认知来说也只能到这步,剩下的如何进阶就要靠我日后努力了。
先说一下关于静幀的fg优化,其实fg它是一种模拟光子的一种技术,并不是真正的GI。由于真正的GI速度和可控性上面很难拿捏,渲染效率上也比较慢,相对来说,在动画渲染上面还是采用fg的情况比较多。其他大制作公司我不了解,所以不敢妄下结论,所以只讨论fg的部分,至于有兴趣了解GI的朋友们,网上有很多相关的教程请自行查找观看。
先说说fg,我理解的意思就是一种以摄像机为发射点的采样射线,它具备像GI那样的反弹功能,但是这种反弹的功能只是一种模拟,而不是真正的像GI那样具有真实反弹的效果,在现实世界中,我们经常会看见这种现象,如下图:

世界上如果只有光线,而没有反弹,那么世界上物体的暗部将一片死黑,正因为有了光线的反弹,才能有暗部的结构 ,那么mr当中的fg如何优化呢,首先在静幀的情况,基本的选项都处于渲染设置的这里,如下图红框内:
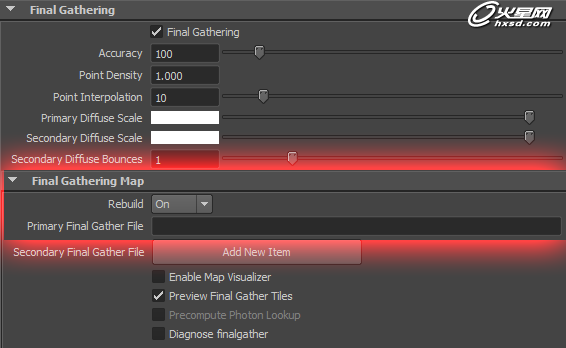
这一选项分别控制fg射线的重新计算的可控,和存储fg射线图片的位置,Rebuild分别为开启、关闭、冻结,这3项在实际的渲染中起到至关重要的作用,如下图:

那么这几个选项在何种情况下使用呢,下面就来说一下:
第一种情况,当Rebuild为On,也就是打开的时候,fg是每次都会在场景中重新计算,可想而知,这样是非常费时的,但是在渲染初期我们还没有达到想要的效果的时候最好保持这种状态,以低质量的渲染品质渲染场景,一旦达到自己比较满意的结果之后就要用到下面的情况,也就是第二种。
第二种情况,一旦渲染效果已经很满意了,那就切换Rebuild为Freeze状态,然后渲染,这个时候会将你所渲染的FG冻结以便后续使用,然后在切换渲染品质到成品级别进行渲染。因为是静幀,此时的的状态也可以切换至off进行预渲染,因为fg射线是随着摄像机的变化儿改变,所以在摄像机在场景中没有变换移动的情况下,2种情况均可。如果想达到更为快速的情况,可以将此时的fg生成贴图,具体操作是将以下的选项激活,将勾勾上,就可以在你自己设置的项目工程目录的renderData\mentalray\finalgMap路径里生成一种叫做fgmap的贴图,然后再次渲染成品品质,此时的速度可以自己尝试对比,会提升很多,因为fg贴图已经计算,不再重复计算。
下面主要再讲一下,关于场景中有透明贴图物体的优化问题。
很多项目都会用到有透明贴图的物体,那么很多时候这样的物体越多,比如树木上的树木,那么渲染的会越慢。在mr中也不例外,但是mr自身有节点可以对其的渲染速度进行大幅度的优化,如果不了解,会产生mr这个渲染器太落后了,太慢啦的误区,但是如果真正了解了mr,其实它的速度不比任何一款渲染器慢,大多数技术应用范围只取决于人而非渲染器。
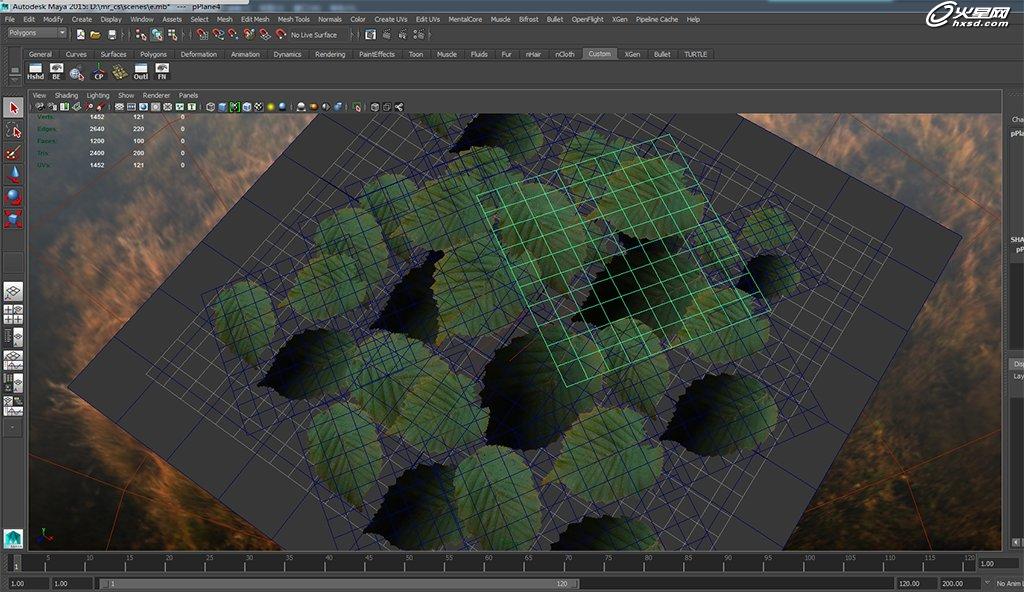
那么来看一下一个简单的场景,这样的情况就是用到透明贴图的场景,如下图:
那么默认的blinn连接节点方式所用到的渲染时间如下:
(我将所有shader的反射高光归0,以保证不同shader在相对公平的情况下渲染,注意这只是测试,不是注重效果的渲染)。
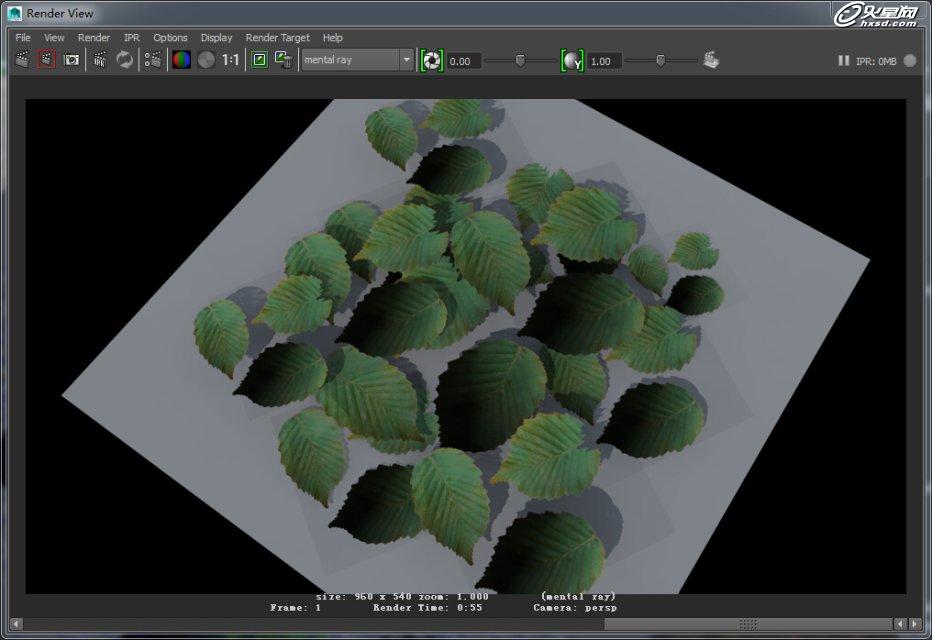
如果按照默认连接渲染时间为55秒。(注意此场景已经采用IBL灯光辅助照射并且开启fg,而且渲染质量控制为成品品质)。
相对应的shader节点连接如图:(节点连接最终的目的是要以最精简的方式去达到效果,而不是说谁连的节点越多越牛)。
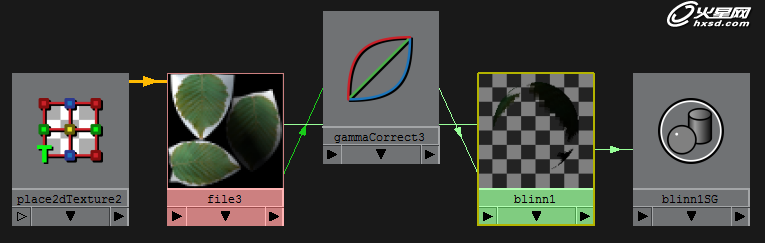
此为默认连接,我们可以看见默认连接的弊端第一是渲染时间慢,第二我们看见透明贴图周边的通道并木有完全抠干净,如下图红框内:

当然以Maya自身的shader是可以做出很干净的通道的,稍后,莫急!
下面来看一下mr的自身shader,也是前面提过很多次的mia_material_x_passes,渲染时间如下图:
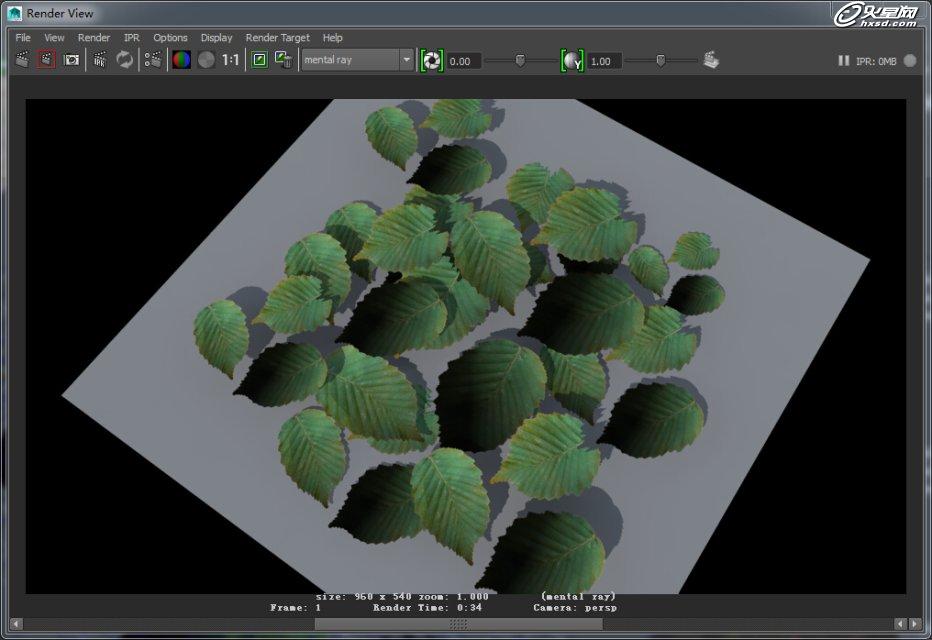
时间缩短为34秒,这就是以shader为优化的结果,时间大幅度缩短,再看通道边缘超级干净,毫无瑕疵,而且节点连接也很简单,如下图:
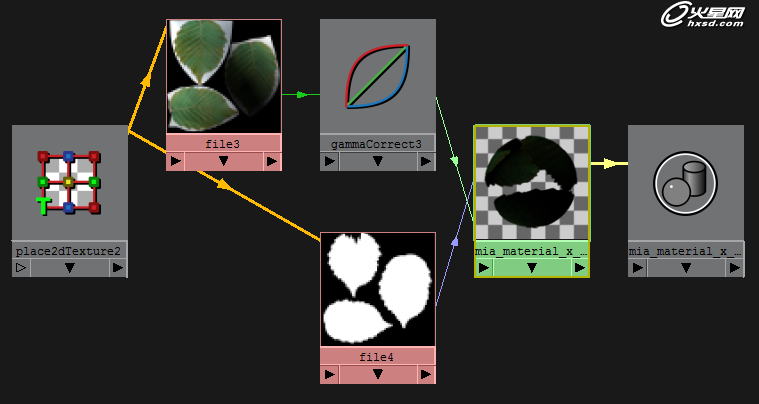
之所以通道如此干净是因为mia_material_x_passes节点自身具有一种剪切技术,可以完全将透明部分剪切掉,如下图:

那么之前说过maya自身的shader如何干净的扣掉alpha,mr自身提供了节点为其服务(可能还有别的方法,但是我用这种),先看一下这种连接的渲染时间:

渲染时间虽然不如第二种,但是介于第一种和第二种之间,而且可以连接任意Maya shader,看一下节点连接:

用第二种和第三种的方法制作的好处不光是透明通道剔除的很干净,而且fg影像会显示你alpha通道的形状,如下图:我把shader改成红色自发光,并且隐藏面片,看看2者的区别 :


可以看见经过mr连接后fg更符合alpha通道的形状。
最后希望国内的同行互相交流的环境越来越好,只有共同的交流,才有不断的提升,技术和知识永远不是用来收藏的,而是用来互动交流的,否则就成了一潭死水,好啦,就写到着吧,有机会还会发些小文章与大家交流!




-

2101期学员李思庭作品
-

2104期学员林雪茹作品
-

2107期学员赵凌作品
-

2107期学员赵燃作品
-

2106期学员徐正浩作品
-

2106期学员弓莉作品
-

2105期学员白羽新作品
-

2107期学员王佳蕊作品
热门课程
专业讲师指导 快速摆脱技能困惑



相关文章
多种教程 总有一个适合自己专业问题咨询
你担心的问题,火星帮你解答-
为给新片造势,迪士尼这次豁出去了,拿出压箱底的一众经典IP,开启了梦幻联动朱迪和尼克奉命潜入偏远地带卧底调查 截至11月24日......
-
此前Q2问答环节,邹涛曾将《解限机》首发失利归结于“商业化保守”和“灰产猖獗”,导致预想设计与实际游玩效果偏差大,且表示该游戏......
-
2025 Google Play年度游戏颁奖:洞察移动游戏新趋势
玩家无需四处收集实体卡,轻点屏幕就能开启惊喜开包之旅,享受收集与对战乐趣库洛游戏的《鸣潮》斩获“最佳持续运营游戏”大奖,这不仅......
-
说明:文中所有的配图均来源于网络 在人们的常规认知里,游戏引擎领域的两大巨头似乎更倾向于在各自赛道上激烈竞争,然而,只要时间足......
-
在行政服务优化层面,办法提出压缩国产网络游戏审核周期,在朝阳、海淀等重点区将审批纳入综合窗口;完善版权服务机制,将游戏素材著作......
-
未毕业先就业、组团入职、扎堆拿offer...这种好事,再多来一打!
众所周知,火星有完善的就业推荐服务图为火星校园招聘会现场对火星同学们来说,金三银四、金九银十并不是找工作的唯一良机火星时代教育......
